













阿里巴巴集团智能计算研究院日前上线了一款新的 AI 图片-音频-视频模型技术EMO,官方称其为“一种富有表现力的音频驱动的肖像视频生成框架”。
只需要一张照片和一段音频,就能生成一段说话唱歌类型的视频。操作比较简单,而且视频时长没有限制。根据视频案例,EMO生成的视频,动态、表情都十分逼真,让很多用户玩的不亦乐乎。
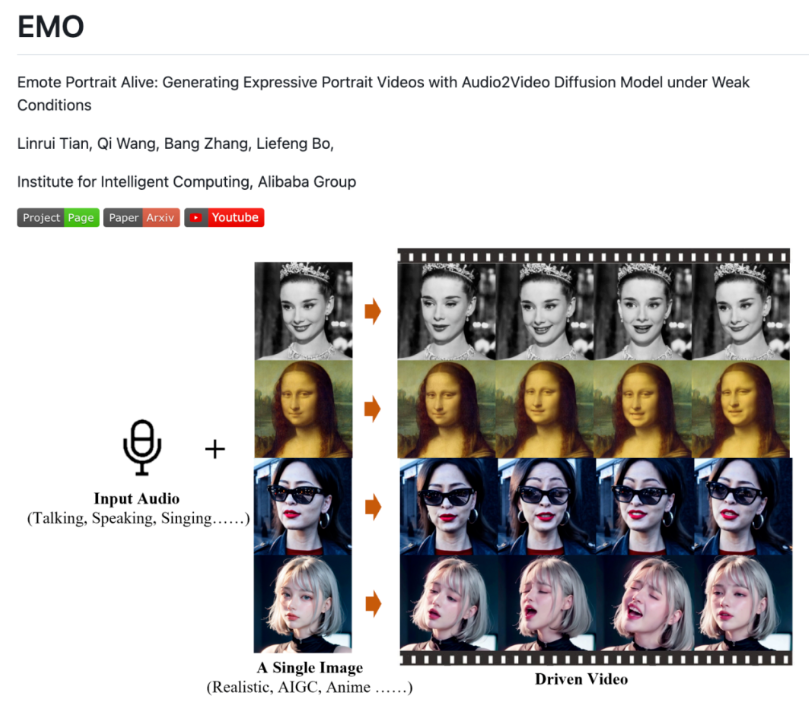
很多AI合成视频一眼就能看出来,因为面部表情僵硬,和语言动作根本不匹配。而EMO引入了速度控制器和面部区域控制器,可以把控面部微表情,使得视频更具有表现力。观看网友制作的视频,视频人物在唱歌时还可以根据歌曲的情感变化而出现面部表情的细腻变化,非常传神。
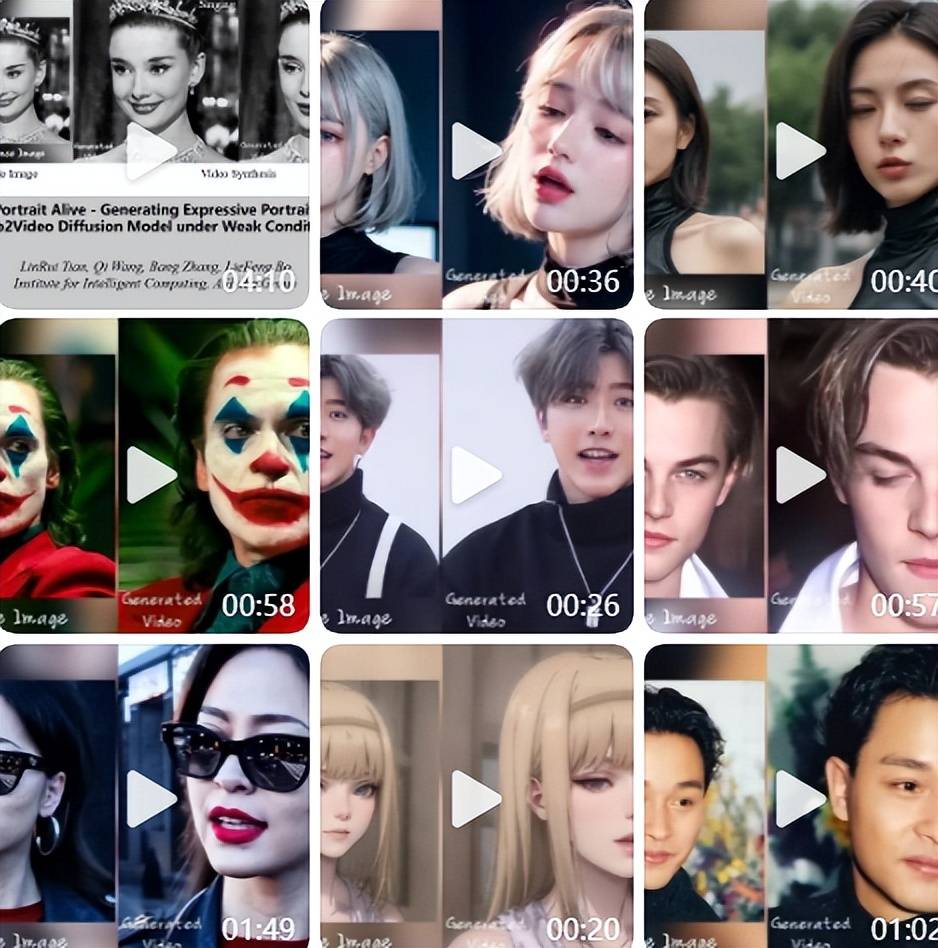
《狂飙》电视剧中“高启强”畅谈罗翔普法;蔡徐坤的一张图片,就能通过其他音频配合“唱出”一首rapper饶舌,连口型都几乎一模一样;甚至前不久OpenAI发布的Sora案例视频里面,一位 AI 生成的带墨镜的日本街头女主角,现在不仅能让她开口说话,而且还能唱出好听的歌曲。

EMO还拥有音频驱动的人像视频生成,表情丰富的动态渲染,多种头部转向姿势支持、增加视频的动态性和真实感,支持多种语言和肖像风格,快速节奏同步,跨演员表现转换等多个特点与功能。

EMO框架上线到GitHub中,相关论文也在arxiv上公开。
GitHub:https://github.com/HumanAIGC/EMO
论文地址:https://arxiv.org/abs/2402.17485
相关导航





暂无评论...